
|
日記・備考録 |
2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013/ 1 2 3 4 5 6 7 8 9 10 11 12 | 2014 |
| August | September 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
October | Home |
...................................................................................................................................
ということで、結論としてはHaswellもGeForce GTX Titanも期待はずれ。まあ性能引き出せてないだけ、という可能性もあるので気長に色々といじるつもり。
-------------------------------------
ここまできたら、ということでGeFore GTX Titan CUBLASによる行列乗算速度を測る。
matmul() 200 x 200: time= 0.515 s ( 31.0
MFLOPS)
matmul() 500 x 500: time= 0.004 s ( 62437.5
MFLOPS)
matmul() 1000 x 1000: time= 0.018 s (111055.6
MFLOPS)
matmul() 2000 x 2000: time= 0.110 s (145418.2
MFLOPS)
matmul() 5000 x 5000: time= 1.327 s (188376.0
MFLOPS)
matmul() 10000 x 10000: time= 9.894 s (202132.6
MFLOPS)
まあ速いんだけどOCした3960Xよりちょっと速いくらいだし、最大でも15000×15000までしか計算できない。プログラムを色々と直さなければいけない手間と値段を考えると、導入効果は微妙。どうしたら1TFLOPS超の性能を使いきれるのだろう。
補足: GeForce GTX Titanを高速化するためには設定でDP有効化が必要な様。追加情報を10/6に書いた。(10/6追記)
-------------------------------------
ついでなので放っておいたGeForce GTX Titanを入れて、NVDIAのドライバとcuda-5.5を入れてみた。CUBLASのサンプルプログラムmatrixMulCUBLASを実行してみた。
[Matrix Multiply CUBLAS] - Starting...
GPU Device 0: "GeForce GTX TITAN"
with compute capability 3.5
MatrixA(320,640), MatrixB(320,640), MatrixC(320,640)
Computing result using CUBLAS...done.
Performance= 1399.56 GFlop/s, Time= 0.094
msec, Size= 131072000 Ops
Computing result using host CPU...done.
Comparing CUBLAS Matrix Multiply with CPU
results: PASS
この表示が本当なら1.4TFLOPS出ていることになるけど、まさかね。
補足: サンプルコードの中身見たら単精度 (sgemm) みたい。
-------------------------------------
ついでなのでMKLによる行列演算速度も測ってみた。
i7 4770K (MKL 10.3)
matmul() 200 x 200: time= 0.002 s ( 7980.0
MFLOPS)
matmul() 500 x 500: time= 0.003 s ( 83250.0
MFLOPS)
matmul() 1000 x 1000: time= 0.024 s ( 83291.7
MFLOPS)
matmul() 2000 x 2000: time= 0.166 s ( 96361.4
MFLOPS)
matmul() 5000 x 5000: time= 2.425 s (103082.5
MFLOPS)
matmul() 10000 x 10000: time= 19.085 s (104789.1
MFLOPS)
solve() 200 x 200: time= 0.001 s
solve() 500 x 500: time= 0.006 s
solve() 1000 x 1000: time= 0.037 s
solve() 2000 x 2000: time= 0.255 s
solve() 5000 x 5000: time= 3.615 s
solve() 10000 x 10000: time= 27.344 s
i7 2600K (MKL 10.3)
matmul() 200 x 200: time= 0.012 s ( 1330.0
MFLOPS)
matmul() 500 x 500: time= 0.008 s ( 31218.8
MFLOPS)
matmul() 1000 x 1000: time= 0.024 s ( 83291.7
MFLOPS)
matmul() 2000 x 2000: time= 0.142 s (112647.9
MFLOPS)
matmul() 5000 x 5000: time= 2.075 s (120469.9
MFLOPS)
matmul() 10000 x 10000: time= 15.955 s (125346.3
MFLOPS)
solve() 200 x 200: time= 0.101 s
solve() 500 x 500: time= 0.015 s
solve() 1000 x 1000: time= 0.036 s
solve() 2000 x 2000: time= 0.235 s
solve() 5000 x 5000: time= 3.176 s
solve() 10000 x 10000: time= 23.715 s
ということでHaswell、捨てた方が良い気がしてきた。(4770Kはノーマル, 2600Kは少しOCしている)
-------------------------------------
icc入れて測ってみた。
with AVX2 (i7 4770K, icc 12.1.3)
N= 4096 DOT21= 0.001 DOT22= 0.002 DOT23=
0.003 ms
N= 8192 DOT21= 0.003 DOT22= 0.004 DOT23=
0.005 ms
N= 16384 DOT21= 0.001 DOT22= 0.002 DOT23=
0.002 ms
N= 32768 DOT21= 0.002 DOT22= 0.004 DOT23=
0.005 ms
N= 65536 DOT21= 0.007 DOT22= 0.010 DOT23=
0.013 ms
N= 80000 DOT21= 0.009 DOT22= 0.012 DOT23=
0.016 ms
N=104000 DOT21= 0.012 DOT22= 0.016 DOT23=
0.020 ms
N=131072 DOT21= 0.015 DOT22= 0.020 DOT23=
0.026 ms
速くならないなあ。メモリ帯域不足か。これだと16Mspsでせいぜい60chというところか。
-------------------------------------
OSインストール出来ずに放ってあったHaswellのPCをなんとか再インストール。どうも起動ディスクにパーティション区切るとダメっぽい。目的はAVX2の性能測定。ubuntu 13.04のgcc 4.7.2ではAVX2は既にサポートされていて、コンパイラオプション -march=core-avx2 -mavx2 をつければ有効になる様。ということで、積和演算あたりを256bit SIMDに書き変えて実行時間を測る。(Core i7 4770K, 3.5GHz, RAM 16GB, ubuntu 13.04 64bit, gcc 4.7.3, シングルスレッド, 一番下はi7 2600K, gcc 4.5.2)
with AVX2 (i7 4770K, gcc 4.7.3):
N= 4096 DOT21= 0.001 DOT22= 0.002 DOT23=
0.003 ms
N= 8192 DOT21= 0.002 DOT22= 0.001 DOT23=
0.001 ms
N= 16384 DOT21= 0.001 DOT22= 0.002 DOT23=
0.002 ms
N= 32768 DOT21= 0.003 DOT22= 0.004 DOT23=
0.006 ms
N= 65536 DOT21= 0.007 DOT22= 0.010 DOT23=
0.013 ms
N= 80000 DOT21= 0.009 DOT22= 0.012 DOT23=
0.015 ms
N=104000 DOT21= 0.012 DOT22= 0.016 DOT23=
0.020 ms
N=131072 DOT21= 0.015 DOT22= 0.020 DOT23=
0.025 ms
with SSE2 (i7 4770K, gcc 4.7.3):
N= 4096 DOT21= 0.002 DOT22= 0.003 DOT23=
0.004 ms
N= 8192 DOT21= 0.001 DOT22= 0.001 DOT23=
0.002 ms
N= 16384 DOT21= 0.002 DOT22= 0.002 DOT23=
0.003 ms
N= 32768 DOT21= 0.003 DOT22= 0.005 DOT23=
0.007 ms
N= 65536 DOT21= 0.008 DOT22= 0.011 DOT23=
0.014 ms
N= 80000 DOT21= 0.010 DOT22= 0.013 DOT23=
0.017 ms
N=104000 DOT21= 0.013 DOT22= 0.017 DOT23=
0.023 ms
N=131072 DOT21= 0.016 DOT22= 0.022 DOT23=
0.029 ms
with SSE2 (i7 2600K, gcc 4.5.2):
N= 4096 DOT21= 0.001 DOT22= 0.002 DOT23=
0.002 ms
N= 8192 DOT21= 0.002 DOT22= 0.003 DOT23=
0.004 ms
N= 16384 DOT21= 0.002 DOT22= 0.002 DOT23=
0.003 ms
N= 32768 DOT21= 0.004 DOT22= 0.005 DOT23=
0.007 ms
N= 65536 DOT21= 0.009 DOT22= 0.012 DOT23=
0.016 ms
N= 80000 DOT21= 0.011 DOT22= 0.015 DOT23=
0.019 ms
N=104000 DOT21= 0.014 DOT22= 0.020 DOT23=
0.025 ms
N=131072 DOT21= 0.018 DOT22= 0.025 DOT23=
0.032 ms
残念。ほとんんど速くならない。メモリ帯域が飽和しているのかな。例えばDOT21の1回の演算にはメモリから2Byteデータを3つ取ってくる必要があるから、所要メモリ帯域は、3×2×131072/0.016e-3=49.2GB/s。DDR3-1600 デュアルCHの帯域は25.6GB/sだけど、これ位のサイズだとほぼキャッシュに入るはずだから、もう少し性能が出ても良い気がする。コンパイラICCに替えてみるか。
...................................................................................................................................
屋根の上に常設しているGPS-702-GGが逝ったっぽい。急に全信号のC/N0が10dB以上落ちて回復しない。このアンテナ2台買って6年目だけどこれで3回目、1回目はLNA故障で修理交換、2回目は故障したまま。今修理すると多分全交換になって修理代が\6万位。明日、コネクタ等が緩んでないか確認するけど復旧しないだろうなあ。NovAtelのGPS-70X、安くて高性能の、いいアンテナだと思うのだけど、基準局用にはちょっとヤワな感じ。
-------------------------------------
よく考えたら、long-codeにPLL入れてあげるとshort-codeはI-chだけ相関とれば良いから、シリアル探索時間を半分に減らせる。これでAVX2も使うとして、実行時間は、 (1) 4ms切り出し (2) キャリア乗算 (26μs) (3) long-code DLL/PLL (29μs) (4) short-code 探索 (3μs×128=384μs) 合計 0.44 ms (i7 4770K, シングルスレッド) となる。Haswellタブレット (例えばこれ) でも十分動くということになるけど、これどこか計算間違ってない?
ところで、Javadの新しい受信機、なんかLEX受信のために256ch使うって噂で聞いたんだけど、これホント? もしホントなら物凄い力任せの実装だなあ。
-------------------------------------
自作PC界隈では最近話題のNUCなのだけど、ちょっと閃いて買ってしまった。Core i5-3427U, RAM 4GB, SSD 64GBでubuntu 13.04インストール済み。目的は予想の通り。残念ながらHaswellではないので、16Mspsで24ch位かなあ。でもGPS+GLO+QZS L1なら楽勝。問題はLEXが間に合うか、ということでここ1週間くらい検討しているのである。
補足: まだ出てないみたいだけど、次買うとするとこれあたり。(19:26追記)
...................................................................................................................................
今回LEX受信機用に、新しめのCPUでちゃんと速度測ったのだけど、Core i7 4770K (4コア) あたりなら、SDRでも 40Mspsで50 ch、16Mspsなら120 ch以上いけそう。もちろんAVX2のコード追加してメモリ帯域が足りるとして。
-------------------------------------
マルチスレッドにしたらどうだろう。
MKL 10.3 (NFFTTHREAD=2):
N= 4096 FFT= 0.064 IFFT= 0.047 CONV= 0.105
ms
N= 8192 FFT= 0.034 IFFT= 0.026 CONV= 0.079
ms
N= 16384 FFT= 0.038 IFFT= 0.044 CONV= 0.125
ms
N= 32768 FFT= 0.077 IFFT= 0.072 CONV= 0.236
ms
N= 65536 FFT= 0.132 IFFT= 0.128 CONV= 0.425
ms
N= 80000 FFT= 0.199 IFFT= 0.191 CONV= 0.594
ms
N=104000 FFT= 0.283 IFFT= 0.284 CONV= 0.819
ms
N=131072 FFT= 0.255 IFFT= 0.244 CONV= 0.825
ms
おお、圧倒的に速い!! でもスレッド数2にしたはずなのに4コア共負荷100%になるな。
FFTW、マルチスレッド実装が悪いということ。これビルドの仕方で何とかならないのか。
-------------------------------------
まだ、FFTの実行時間ちまちまと測っている訳だが、MKLにFFTWのラッパが付いていることを思い出した。ラッパ使うためには、
> cd /opt/intel/interfaces/ffw3xf
> sudo make libintel64 compiler=gnu
とやって出来たlibfftw3xf_gnu.aをリンクすれば良い
(もちろんMKLのリンクも必要)
結果、MKL 10.3:
N= 4096 FFT= 0.070 IFFT= 0.062 CONV= 0.133
ms
N= 8192 FFT= 0.077 IFFT= 0.078 CONV= 0.176
ms
N= 16384 FFT= 0.179 IFFT= 0.179 CONV= 0.396
ms
N= 32768 FFT= 0.384 IFFT= 0.385 CONV= 0.843
ms
N= 65536 FFT= 0.816 IFFT= 0.817 CONV= 1.786
ms
N= 80000 FFT= 1.006 IFFT= 1.005 CONV= 2.197
ms
N=104000 FFT= 1.337 IFFT= 1.337 CONV= 2.922
ms
N=131072 FFT= 1.685 IFFT= 1.684 CONV= 3.677
ms
FFTW 3.2.4:
N= 4096 FFT= 0.052 IFFT= 0.041 CONV= 0.093
ms
N= 8192 FFT= 0.074 IFFT= 0.073 CONV= 0.166
ms
N= 16384 FFT= 0.121 IFFT= 0.121 CONV= 0.280
ms
N= 32768 FFT= 0.216 IFFT= 0.265 CONV= 0.606
ms
N= 65536 FFT= 0.438 IFFT= 0.434 CONV= 1.019
ms
N= 80000 FFT= 0.943 IFFT= 0.941 CONV= 2.060
ms
N=104000 FFT= 1.403 IFFT= 1.404 CONV= 3.039
ms
N=131072 FFT= 1.642 IFFT= 1.676 CONV= 3.805
ms
残念。殆ど変わらない。(両方ともシングルスレッド)
-------------------------------------
K.Nakakuki et al., An Efficient Acquisition Method for the CSK Signal of QZSS LEX, ION GNSS+ 2013
Spriral, Optimized Sparse Fast Fourier Transform
まだちゃんと読んでないけど、鈴木君から今年のIONでの発表とsparse FFTライブラリ教えてもらった。どうも有難う。L1C/Aアシストに使わないって、計算量的にかなり大変そうだけど成立性あるのかなあ (まあ、古野の受信機はLEXだけしか追尾してないから成立性はあるか。でもLEXって信号のみからは時刻情報得られないので、週替わりのlong-codeリセットが不可能で、結局何らかの時刻を外部から入れてあげる必要がある。これは信号・航法データ設計の不備だと思う。)
-------------------------------------
昨日から書いているLEXリアルタイムSDRの検討、計算量的には20Mspsにしてlong-code
DLL実装し、short codeはシリアル探索するのが最も効率良さそう。これだと
(1) 4ms切り出し (2) キャリア乗算 (52μs)
(3) long-code DLL (57μs) (4) short-code
探索 (12μs×128=1.54ms) 合計 1.65 ms、となる
(i7 2600K、シングルスレッド)。L1C/AのDLLを入れてもi5
1コアで十分入るという感じ。Haswellなら概ね半分で楽勝。問題は探索に平均は1.54msでも最悪12μs×256=3.07msかかるところ。あと、long-code DLLの実装はかなりコード量が増えてしまう。
ちなみに、FFTだと (1) 4ms切り出し (2) キャリア乗算
(52μs) (3) 複素変換 (287μs) (4) short-code
FFT検索 (2.05 ms) 合計 2.39 ms。(3) は遅すぎるのでSIMDで書き直すとしても、i5 1コアでギリギリか。
補足: 良く考えたら、long-codeはDLLだけでPLLの実装はいらないので若干コード量は減らせる。(ドップラはL1C/Aで追いかける前提) (12:27追記)
再補足: VAIO Pro 13" (Core i7 4500U)
のVMware環境下で測った結果からの実行時間予測
(シングルスレッド)。HaswellだけどAVX2は使っていない。
シリアル探索: 72μs + 180μs + 15μs × 128
= 2.17 ms
FFT: 72μs + 45μs + 3.13 ms = 3.25 ms
マルチスレッドFFTはなぜか倍くらい遅い。これはhyper-threading
onになっているからかも。(13:08追記)
-------------------------------------
QSSのwebサイトができた様。これ見ると衛星打ち上げは3機共に2017年度。GPS 2周波の数少ないと思ったらL2Cしかカウントしてないのか。確かにL2P(Y) って元々軍事用だけど皆民生用にも使っている訳で。ところでQZSS対応のチップって既に SiRF/CSR, MTK, u-blox, STMicro, Sonyも出してるのでぜひ表更新しておいて下さい (他にもあったっけ)。
-------------------------------------
GPS/GNSSシンポジウム2013, 2013年10月29-31日, 東京海洋大学
10/30の午後後半に何か話すことになりそう。でも最近ネタ切れ。
-------------------------------------
Haswellで追加された256bit SIMD演算 (VPMADDW, _mm256_madd_epi16()) では1命令で16 bit×16データの積和ができる。これ使うと相関器速度を倍にできる。最新のノートPCは皆Haswellだから追加実装してもよいかも。
-------------------------------------
u-blox, u-blox release improved sub-meter GPS positioning module NEO-7P, September 24, 2013
正式リリース来たけど、やっぱりGPS以外のrawは出ないみたい。
...................................................................................................................................
ついでにSSE2による相関器性能。gnss-sdrlibの関数ではdot_21()。
N= 80000 DOT21= 0.012 ms
N=104000 DOT21= 0.015 ms
これはI/Q同時に相関をとる関数。なので、平均128回の相関探索で2
ms。探索ステップを1シンボルとするとC/N0が悪い状況で相関ピークを見失う可能性がある。ステップを1/2シンボルとすると4
ms。結論からするとやっぱりFFTかなあ。FFTWがあと2倍速ければ十分なのだけど。
ちなみにSSE2使わない相関器速度は、
N= 80000 DOT21= 0.217 ms
N=104000 DOT21= 0.282 ms
で10倍以上遅い。これではちょっと使い物にならない。なおdot_21() の実装は汎用性を重視して16bit×16bit固定小数なので、実は8bit×2bitまでビット数削減できる。でもこれ最初からSIMDコード書きなおす必要があるのでちょっとしんどい。
補足: 思い出したけど16bit×16bitになっているのはSSE2の積和演算をそのまま使うため。オーバーフローも考えて。ここでの最適化は難しい。(9/25追記)
-------------------------------------
FFTW 3.3.3を自分でビルドして入れてみたけど速くならない。ubuntuのFFTWは既にAVXもenableになっている様。
-------------------------------------
実行時間測るのが先かなあと思って性能測る。gnss-sdrlibのFFTライブラリ。環境はCore i7 2600K + ubuntu 11.04。上からubuntu標準のFFTW3Fを1, 2, 3スレッドで使っている。CONVがFFTによる並列相関。N=80000が20Msps, N=104000が26Mspsで4ms。これ見るとi7であれば何とか行けそうな気はするのだけど。なおFFTWの場合、nを2のべき乗にしなくてもちょっと効率落ちるけどそれなりに性能出る様。
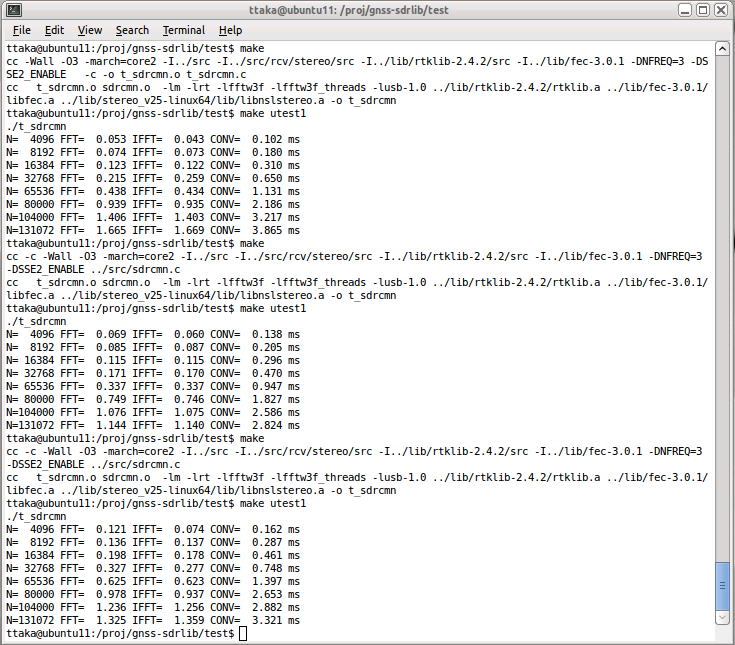
-------------------------------------
鈴木君からsdrlex.cのコード貰った。こんな単純なコードで行けるんだ、と勉強になる。でもstereo標準26Mspsサンプリングでは、ディスクトップPCでもギリギリFFTの計算が間に合わないとのこと。以前FFTWの速度測ったときには、131KのFFTに3.8msかかっていた (i7 2600K) のでありそうな話ではある。実は i5 2コア程度のCPUでLEX受信機を構築したいと思っているので現状コードではかなり厳しい。ということで高速化を考える。
(1) FFTW以外のFFT使う。でもこれ見ると2^17で2msとかにするのは厳しそう。精度いらないから固定小数点FFTでもっと速いのを探す。あるいは勉強してFFT自分で書く。
(2) サンプリングを20Mspsに落とす。ただ4ms
80K (20M) でも104K (26M) でも2^17なので、FFT実行時間は多分変わらない。65Kしか使わないというのは有り得る。これでFFT時間半分。ただしロスがlog10(65/80)*10=-0.9dB。
(3) シリアルサーチに変更。普通にはFFTより速いはずないのだけど、LEXの場合PSKのシフト量は8bit
(0-255) に制限されているので、探索は全体の3%
(2^8/2^13) で良い。以前測った時には131Kの相関で15μs位
(core 2 2.8GHz)。疎サーチ15μs×104/131x2x128=3ms。×2はI/Q、×128は平均半分の探索で見つかるとして。1/2ステップ探索が必要なら時間倍。core
2からi7でSIMD演算がどれくらい速くなっているかがカギ。AVX2が使えればレジスタ幅が倍になっているので倍近く速くできるかも。
(4) long code使わない前提で考えていたけど、どうせL1C/Aをアシストに使うのでlong
code使った方が3dB電力が得。電離層補正やバイアス校正いらないし。long
codeの長さ1Mなので事前に作っておいて、L1C/Aのコード位相使って4ms
10K分切り出せばよい。
ということでなんとか行けるかもという感じ。最適化ってやりだすと楽しいのよね。
補足: 良く考えたらlong codeとshort code両方使ってコード位相探索するのは、long-code位相とlong-short code間位相差の2次元探索になるので計算量的に成り立たない。L1C/Aでアシストするとしてもlong-code位相を±5サンプル位は探索する必要がある。従って、まずL1C/Aで決めたコードの回りでlong codeのみで位相探索してlong-code位相を決めたあと、long-short code位相差を探索する必要がある。これって良く考えたらlong-codeをDLL追尾するところまでやらないと意味がない。ということでshort-code位相探索だけでまずはやってみよう。以前考えた様に1シンボルずれはRS複合で検出・訂正する前提で。 (21:26追記)
再補足: preambleは±1シンボルずれも含めて3種類探索する前提。(23:50追記)
...................................................................................................................................
JAXA実績評価で「衛星測位プログラム」の23, 24年度評価がSになっていて、その根拠として「エクストラサクセスを上回る成果」としてMADOCAの開発が上げられている。
-------------------------------------
Professional Surveyor Magazine, GNSS Next: Is PPP the Next Flavor of the Month, September, 2013
6月オタワPPP-WSのレポート。MADOCAとRTKLIBの発表についてもちょっと触れている。
-------------------------------------
The Royal Academy of Engineering, Global Navigation Space Systems: reliance and vulnerabilities, March 2011
英国王立工学アカデミーによるGPSの脆弱性に関する調査レポート。良くまとまっているぽいので、後で参照するために貼っておく。
-------------------------------------
GNSS-SDRLIB v.1.0の過負荷の件、単に相関点数の問題だけではないなあ。ブロックしないループでsleepやwait入れなければ必ず負荷100%になるわけで。ということで直し始めたら止まらなくなって、データ構造からプログラム構成まで、かなりの部分書き直すことになってしまった。今のところ、32CH、10衛星追尾で負荷180%位までにはなった (Core i7 2600K)。最初負荷高かったのだけど、SSE2有効にし忘れていることに気づいて有効にしたら負荷半分以下になった。AVXは使えないみたいだけどこれはOSかgccのバージョンが少し古いのかも。ちなみに思惑があってLiunxへの移植も同時に。Linux上ではbuffer overrunの問題でない様。これってpthread実装の問題かなあ。
鈴木君、もしsdrlex.cの実装終わってたらちゃんと動かなくてもいいので、コード下さい。
...................................................................................................................................
C.C Beng, GPS Jamming - Threat Scenarios, CGSIC 2013
直接はGPS jammigがどんな脅威になるか、という発表なのだけど、面白いのは上げられているGPS応用。GPS tracked car insurance, company vehicle tracking, GPS asset tracking, criminal tagging, road user charging等。Jammingの影響として"geo-fenced money transit"なんてのがある。現金輸送車のドアをGPS使ってロックするなんてホントにやっているのかなあ。
-------------------------------------
53rd Meeting of the Civil GPS Service Interface Committee, September 16-17, 2013, Nashville Convention Center US
今週のION GNSS+ 2013の前に行われた、53rd CGSICの資料がもう公開されている。GPS Block IIF-5の打ち上げは10/17予定とのこと。あと、ICD-GPS-870と875という新しいICDが発行されるらしい。詳細は来週のICWGで説明されるのかな?
補足: ちょっと調べてみると、ICD-GPS-870ってとっくに出ていて、既にrevisionはAである。中身はGPS
OCX (next generation operational control
system) とGPSユーザとのインタフェースで、SEMやYUMA
Almanac、NANUのフォーマット等。875の方はどうも一般非公開らしい。ちなみにOCXはGPS
Block III用にRaytheonが開発中で稼働は2014年以降Block 1が2016年の予定。(11:20追記)
-------------------------------------
GPS World, Trimble Introduces Compact OEM Module with Triple Frequency GNSS Support, September 8, 2013
3周波 220 CHで4×5 cmか。これ安ければ欲しいんだけど、\10万以下にはならないんだろうなあ。JAVADは 864 CH (!) らしい。凄いんだけど、商品企画としてあさっての方向向いている気がしないこともない。
-------------------------------------
GPS World, Predicted Ephemeris: Waste of Time or an Untapped Resource, September 18, 2013
現在、GPSOC (GPS Operation Center) が15分毎にpredicted ephemeris (PRED) 作ってFOUO (for official use only) で提供しているって書いている。これ本当なのかなあ。予報暦って技術的にはそれ程難しいことないし、最近のメジャー受信機チップに殆ど入っていて携帯では皆既に使っている訳で。問題はこれが、商業サービスでなく公的な (無償) サービスとして誰でも使えるようになったら何が変わるかという点である。このネタ、実はこれ以上は書けないのである。
...................................................................................................................................
NSLから回答。
> We have reported this problem by few
customers at particular PCs/Laptops.
> We have already prepared a bug fix for
this issue. However, this fix required
> us to change the USB mechanism from
the bottom. We are applying it and
> merging it with many new features for
SW version 2.6 coming no later than
> in a month.
>
> For the time being, we suggest using
a different PC/Laptop which will likely
> not exhibit this issue. We apologize
for any inconvenience caused by this issue
> and we will keep you updated about the
new progress.
やっぱり、LIBUSB関係ライブラリのバグ起因か。1カ月位なら待つかな。
...................................................................................................................................
ホントはこんなことやっている暇ないんだけど、裏で解析流していて待ちの状態なので、GNSS-SDRLIB を少しいじる。目的は、ノートPCでも動くようにCPU負荷軽くするための改造。以前動かしたときはMBP 13"でも100%近くCPU食って、まともに動かなくてちょっと興味失っていたんだけど、この前鈴木君に聞いたら相関波形描くために全CH、多点相関器で動いているとのこと。そりゃ負荷高くなるわ...。
ということで、コード調べてみると片側8点、ということは1CHあたり34点相関計算しているらしい。普通は6点 (I/Q × E/P/L) なので、5倍以上CPU食っていることになる。とりあえずsdr.hの定数 TRKCN を8→1に変えればいいのかなあ。
以前使ったMBPは既に手元にないので、Vaio Proに入れようとしたらlibusbのインストールでハマる。なんか、Windows 8ではセキュリティポリシーが変わって署名がないドライバを簡単に入れられないらしい。Windows 8アホすぎ。どうも再起動してドライバ署名強制を無効にして、テストモードにする必要があるらしい。再起動もチャーム出してスタートアップ設定でメニュー選ぶ必要がある。チャームなんてとっくに無効にしてあるので、これ戻すのにまた時間がかかり、なんだかんだとドライバ入れるだけで3Hくらいかかってしまった。次に、Stereoがトラブル。データ取り込み途中でlibusb中のbuffer overrunで止まってしまう。何度やってもダメ。libusb入れ替えたり、Stereoのパッケージ古いバージョンに入れ替えたりしてもダメ。ケーブル替えたり、USBのポート変えてもダメ。仕方ないので、MinGWをインストールして、StereoのAPをビルドできる様にして、コケているところ追っていったけど、最終的にソース未公開のライブラリ中で止まっていることが分かった。でも、お手上げ。とりあえずNSLに問い合わせのメールは送った。
ということで、やりたいことに全く行きつかず、時間切れ。また時間のある時に。
...................................................................................................................................
H.Kubo et al., Source-rupture process of the 2011 Ibaraki-oki, Japan, earthquake (Mw 7.9) estimated from the joint Inversion of strong-motion and GPS data: Relationship with seamount and Phillippne Sea Plate, Geophysical Research Letters, 2013
H.Kubo and Y.Kakehi, Source Process of the 2011 Tohoku Earthquake Estimated from the Joint Inversion of Teleseismic Body Waves and Geodetic Data Including Seafloor Observation Data: Source Model with Enhanced Reliability by Using Objectively Determined Inversion Settings, BSSA, 2013
2011年東北沖地震およびその最大余震である茨城県沖地震の震源過程を、強震計とGPSデータを使ったジョイントインバージョンで解析している。GPSはGEONETデータとRTKLIB 2.4.1のキネマティックPPPを使って頂いているとのこと。京大 久保さんからは丁寧なお手紙と論文のreprintを送って頂いた。有難う御座いました。
RTKLIBのreferenceになるちゃんとした論文書かなければなあ、とは前からずっと思っているのだけど、結局いまだに果たせず。何時になることやら。
...................................................................................................................................
ちょっと必要があってNANUのリスト作った。2005年から。GENERALは除いている。TYPEの説明はここ。FCSTがforecast outage, UNがunscheduled outage.
NANU: 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013
まあ運用休止と通知時間の一覧が欲しかったのだけど。
...................................................................................................................................
風の噂なんだけどこれ全然参加者が集まってないって聞いたぞ。羽田発だと協力金の分引いても最低6万円/1人だから、親子4人で24万円。ちょっと考えると誰が参加するのだろう、という感じ。まあ、最終的に足らなかったら近くに住んでる人頼んで動員するのかもしれないけど。
補足: ツアーよく見たらJAXAによる特別講演もあるのか。どうもご苦労様です。(14:56追記)
再補足: 島内の足代も全部自前持ちらしい。地図見ると種子島って広すぎて歩いて回るの困難だと思うのだけど、皆どうするのだろう。(21:05追記)
...................................................................................................................................
patch 2.4.2 p4 アップした。試験してる暇ないので、まだBeiDouの測位には未対応。これはできればp5で。
...................................................................................................................................
| Home | by T.Takasu |